AWS Rekognition
Learn how to validation text in PDFs and images via AWS Rekognition.
What is AWS Rekognition?
AWS Rekognition is a service that can be used to extract printed and handwritten text from images and documents with mixed languages and writing styles. In BELLATRIX, we use it to validate the layout of complex PDF documents. The service PAID after some usage each month. However, it is relatively cheaper than many other libraries and services or the cost of developing your own solution.
Usage
——————
You can initialize directly the Rekognition service class. Using the extractOCRTextFromLocalFile method, you can get a list of all text snippets in your document. You can use the validateText method to check whether a particular text sequence appears in your document under specific order.
@Test
public void makeTextExtractionFromPDF() {
var rekognition = new Rekognition();
var textSnippets = rekognition.extractOCRTextFromLocalFile("sampleinvoice.pdf");
textSnippets.forEach(System.out::println);
List<string> expectedTextSnippets = Arrays.asList(
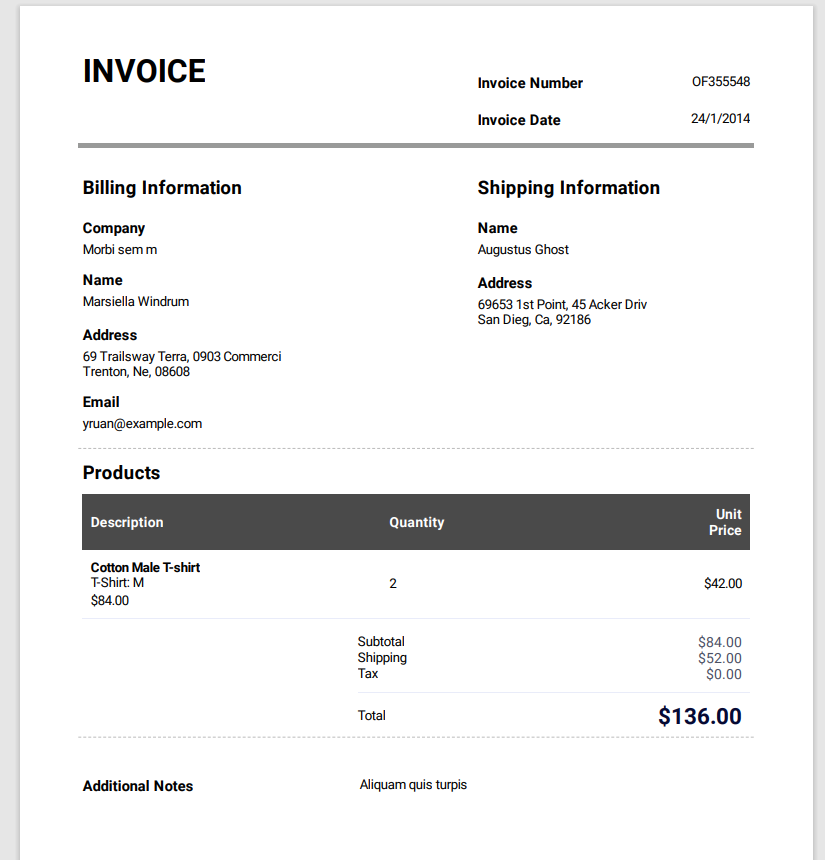
"69653 1st Point, 45 Acker Driv",
"Subtotal",
"$84.00",
"Total",
"$136.00",
);
rekognition.validateText("sampleinvoice.pdf", expectedTextSnippets);
}
You are not limited to PDFs only. You can use the same feature for extracting text from complex images. Similar to the one below.
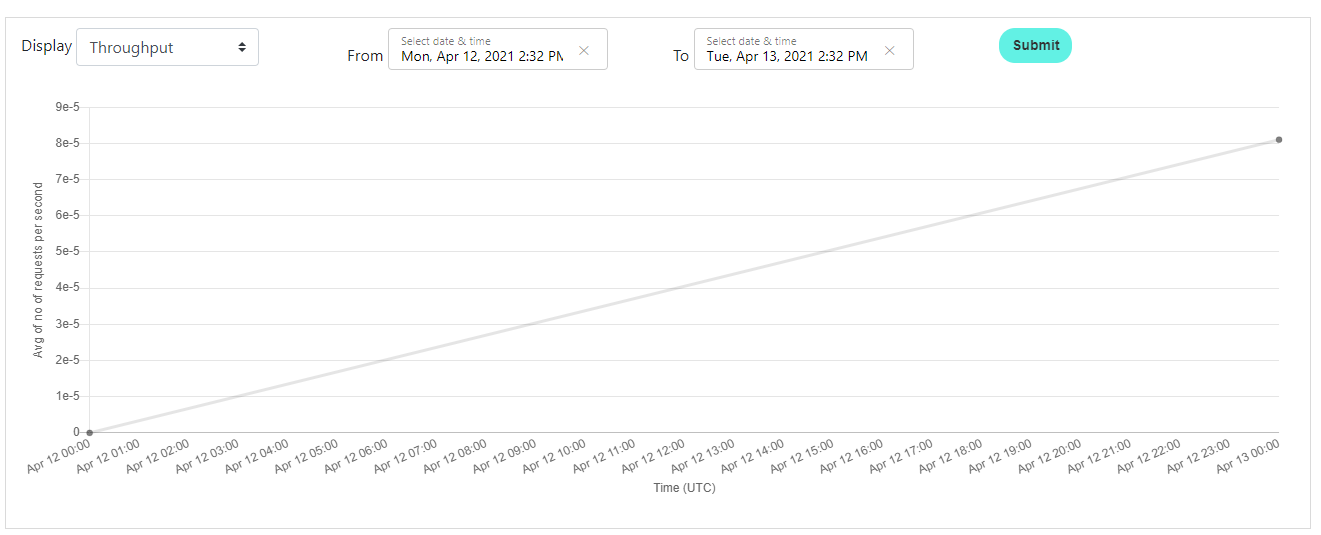 You can use the following code snippet to verify the info.
You can use the following code snippet to verify the info.
@Test
public void ExtractTextFromGraph() {
var rekognition = new Rekognition();
var textSnippets = rekognition.extractOCRTextFromLocalFile("devPortalGraph1.PNG");
textSnippets.forEach(System.out::println);
List<string> expectedTextSnippets = Arrays.asList(
"Apr 12 01:00",
"Apr 13 00:00",
);
rekognition.validateText("devPortalGraph1.PNG", expectedTextSnippets);
}